Data Scraping 5X Faster With Job Sequencer & Request Blocker
October 09, 2017
We are excited to announce a new major features release. This release is focused on giving you greater usability when gathering your data and providing that data in a faster, more efficient way. How much faster? Up to 5X, and in some instances much faster.
We are determined to continue providing the most dynamic and powerful data extraction tool on the market—and this is why we’re always striving to find ways to make Mozenda better with an ever-improving user experience.
The overarching goal of this release is to give you more efficient performance and improved usability. Brett Haskins, our CEO, said “There is no other technology like this in our space. This will be a game changer for our high-volume clients.” Here’s a breakdown of the top three new features.
Job Sequencer
Go here to view our Help Center’s detailed step-by-step guided tutorial of the Job Sequencer feature.
This automated sequences tool facilitates gathering large amounts of data with minimal user intervention. This allows you to:
- Run multiple agents at the same time
- Run multiple jobs simultaneously for faster processing
- Automate the overall process
- Publish to multiple locations
On this new release, Chris Curtis, Mozenda’s System Architect, said, “Most features we create are speculative in nature. We hope users will latch on, realize the value, and use them. This one’s different. We’ve been using the sequencer technology internally for years. This new feature builds on our tried and true internal technology because we’ve found there really is no better way to scrape data.”
Kenny Nielsen, an Account Manager in Mozenda’s Professional Services department who uses the automated sequencer daily to gather large data sets for Mozenda clients, described Job Sequencer this way: “Sequencer is very easy to understand. It’s like setting up dominoes. You have to be strategic about where you put the dominoes, making sure to set each in exactly the right place. Once you have them all set up, the sequencer is the finger that pushes the first domino.”
Running concurrent jobs is a function that is ideal for agents that use data lists to process lists of inputs. (An input list is a list of values you want used during the execution of your agent; for example, product numbers that must be input into a site to pull out the price.) With agents that contain data lists you can use the sequences tool to create many jobs that run simultaneously—job 1 can do items 1-10, job 2 does items 11-20, etc., finishing your project faster than ever. Previously, if your web scraping agent did not include data lists you would not be able to set the run agent step to run multiple concurrent jobs.
Thinking of your data scraping as a sequential process is a paradigm shift you must have in order to realize the full effect of the Job Sequencer in your efforts. Kenny Nielsen, who’s been using our internal sequencing technology for years to service Fortune 500 clients, said, “Once you understand the sequencer paradigm it really opens up automation. We have processes that go through ten steps—even twenty steps—and all we have to do is watch. In contrast, you would need to be manually involved in every one of those steps if you were doing that without the sequencer.”
It’s important to note here that while you can divide your agent into any number of concurrent jobs, your account will still be limited to the number of concurrent jobs allowed by your license. For example, if you set 10 jobs but your account only allows for 5 concurrent jobs, the first 5 will run and the others will be placed in a queue and will run automatically as the other jobs finish.
Using the configuration options to run an agent with multiple concurrent jobs allows you to get your data much faster. Errors in scraping data will continue to occur, but the new update also enables you to automatically diagnose, process, and resume jobs that stop with errors. You can even designate the exact error codes you’d like the system to ignore. This is especially helpful for agents that routinely stop due to website errors that are generally solved by a second attempt at loading the web page.
We’re very excited to be releasing the Job Sequencer because it’s going to have a big impact on the productivity of our users that choose to integrate its features into their processes. Kenny Nielsen also said, “It would pain me to go back to the old way of running things linearly. This is very much the most efficient way to scrape web data. In the old way of doing things, one error would stop your whole process. With the error handling in the sequencer an error doesn’t have to stop the charge. It can save you days, probably even weeks on large projects.”
It’s important to note that Job Sequencer is only available to our enterprise clients, and only account administrators have the permissions needed to create, edit, and delete sequences. Please contact your sales representative at sales@mozenda.com or call +1 (801) 995-4554 for more information about enabling it on your account.
Request Blocker
Go here for more information on the ins and outs of how to use Request Blocking, or contact our support department.
This new feature offers the ability to achieve sizable performance gains—up to 5X, but depending on the site you’re scraping you may see lifts even greater than that.
Chris Curtis, who architected the feature, said of the Request Blocker: “If you use this feature and change your agents to remove and block requests that are unnecessary, they’ll run faster, they’ll produce more consistent results, and you’ll spend less time managing them.”
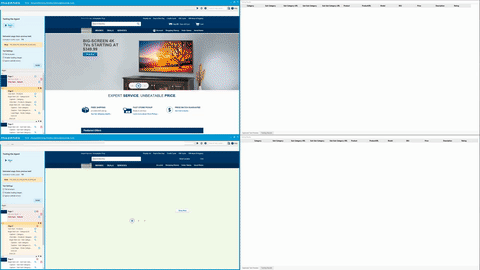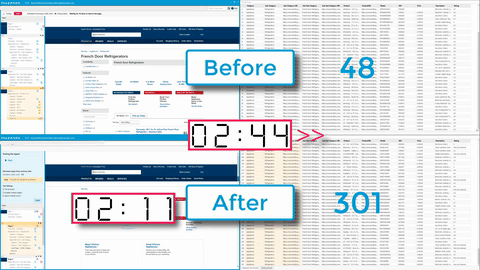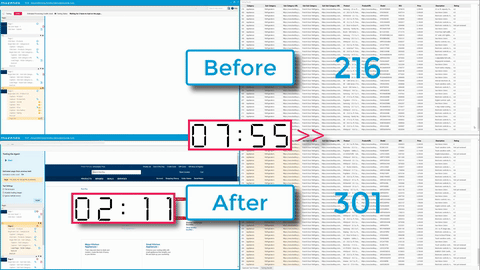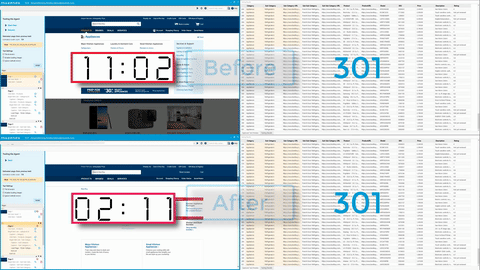
This is another example of a feature we’re releasing after using it internally for years. Internal power users have described the Request Blocker as “Amazing-ness!” and said, “If you use the tool all day, you’ll do anything to get your hands on this feature. It saves you hours and hours. It will change your life.” By using request blocking, you may be able to increase the speed and performance of your agents by up to 200-800%.
Though this functionality has been available for quite some time for the advanced users who knew where to look, we’re now making it accessible for everyone. The new user interface allows you to easily configure blocking expressions that unnecessarily extend agent execution time.
With Request Blocker, you can block requests to ad servers, styling (css), media (videos, music), images, analytics companies, social media websites, and more. The new user interface will guide you in the process of creating expressions to block unnecessary requests made by your agent. This enables you to customize your agents to only request information needed for the agent to successfully load and gather your data, streamlining the process for each of your scrapes and increasing efficiency by up to 5X.
Mike Lloyd, Mozenda’s Quality Assurance Manager, said of the Request Blocker, “The client has more power at their hands to craft a very intelligent agent—and what do you get? You get stability and speed. Any client designing any agent, from quick and easy to something bigger, is going to benefit.”
Publishing
We also have a couple of enhancements to the publishing and exporting functions. You can now publish to Google Drive and export directly into an Excel format.
We use Mozenda for data extraction for ourselves and for our clients, and we’ve seen the new and improved Mozenda gather up to 5X the data 5X faster as we’ve developed these new features. We are excited for you to enjoy a more powerful and user-friendly Mozenda. This new technology allows our clients to extract web data much faster and with less effort than ever before.
Demo Webinar Thursday, October 12th
Want to see these new features in action? Join us for a live Mozenda Training Webinar Thursday, October 12 at 11am Mountain time. Space is limited, so reserve your seat now. At the end of the webinar we will announce a year-end promotion that you won’t want to miss.