Best Practices: Understanding Data Extraction Settings
April 25, 2017
Using Mozenda can be boiled down to two basic components: building agents and running agents.
While the Agent Builder offers an intuitive, browser-based experienced for building agents, many of the settings for running an agent are found in the Web Console. Knowing what these settings are used for and the problems they can solve is crucial to effective data extraction.
Properly adjusting harvesting settings can help resolve many common issues encountered when an agent runs:
- Lost or missing data
- Halted agent
- Incorrect data
In this article, we’ll break down the details of each harvesting setting available and the problems they can resolve.
Settings Descriptions
Below is a long-form summary of each option available in an agent’s harvesting settings. Note that some of these settings do not improve website compatibility and will not help with the issues outlined above. These settings will be marked with an asterisk (*) next to the setting name.
Method
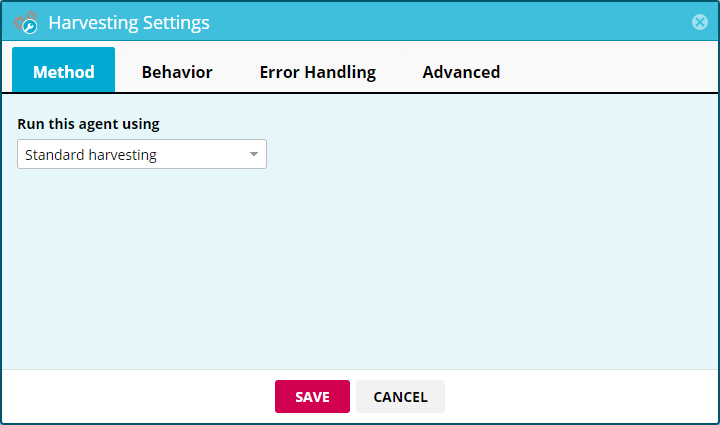
Run this agent using
Default: Standard harvesting (unless the website requires premium harvesting). Standard harvesting loads the website directly through our harvesting servers while premium harvesting accesses the websites through a different geographical location (geolocation).
If a website throttles or blocks rapid traffic coming from the same location, premium harvesting will often resolve the issue. Websites that do this will usually allow an agent to run normally for a few minutes then block all requests, resulting in an error. Adding wait times could resolve the issue, but premium harvesting may also help.
Click here for more information on premium harvesting.
Behavior
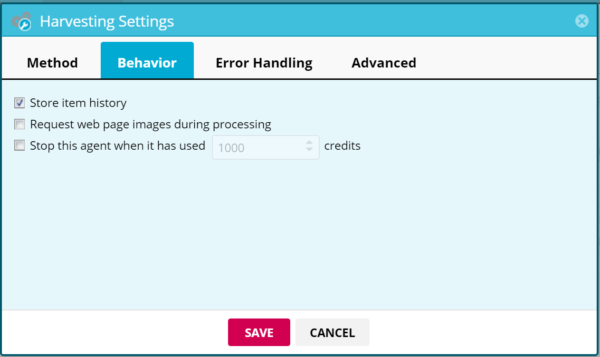
Store item history*
Default: off. When you run a new agent job, the results from all the previous jobs will be saved, in order to view all items ever found with this particular agent.
Request web page images during processing
Default: off. Requesting images slows down agent processing. However, make sure to enable this setting if your agent downloads images.
Stop this agent when it has used _ page credits*
Default: off. Choose a page credit threshold to prevent the agent from using more than the specified limit.
Error Handling
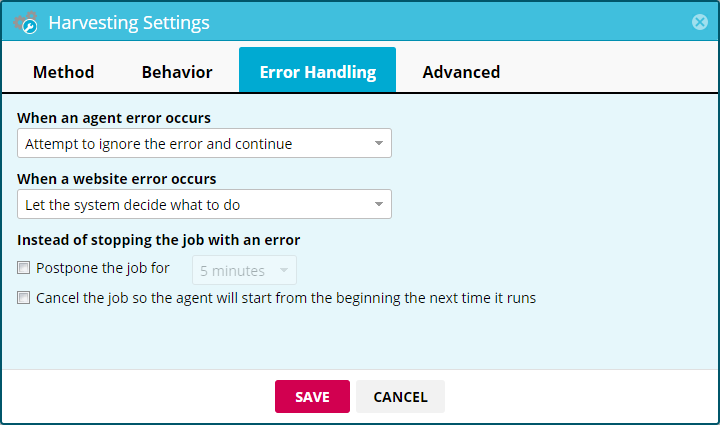
When an agent error occurs
Default: Attempt to ignore the error and continue. The default setting allows some errors to go without stopping the agent. While fewer errors may sound desirable, this could also lead to some loss of data. For example, if a website element is found in a different location between two different pages and there is no alternate location defined, this default setting would simply ignore the missing data.
If you want to avoid data loss and build a robust, thorough agent, set this to “Stop the job so the agent can be fixed” and plan on troubleshooting errors as they arise. If needed, you may skip nonessential items by marking them as optional so you can focus on the most important data points.
When a website error occurs
Default: Let the system decide what to do. In cases where the website itself has an error (e.g., 404 not found), this setting determines the harvesting server’s response. Similar to the previous setting, changing this to “Stop the job so the agent can be fixed” and handling the errors will require some additional attention but yield better results.
In Mozenda, website errors are referred to as INet errors. Click here for more information.
Instead of stopping the job with an error
Default: off. Postponing the job will delay it for the specified time. This could be helpful for websites that load slowly or sometimes not at all. The system will postpone a job up to 30 times before returning an error.
Usually, you will only want to use this setting when you choose to stop the agent when either an agent or website error occurs. If you have fine-tuned an agent for a website and tested it thoroughly, postponing and resuming the agent will ensure that the job completes instead of failing.
This setting can also be used effectively in conjunction with premium harvesting. Since premium harvesting rotates IP addresses during harvesting, there is a small chance that an IP could be blocked on the remote server side, resulting in an error. Postponing the job uses a new IP, which should result in the job processing normally following the error.
Advanced
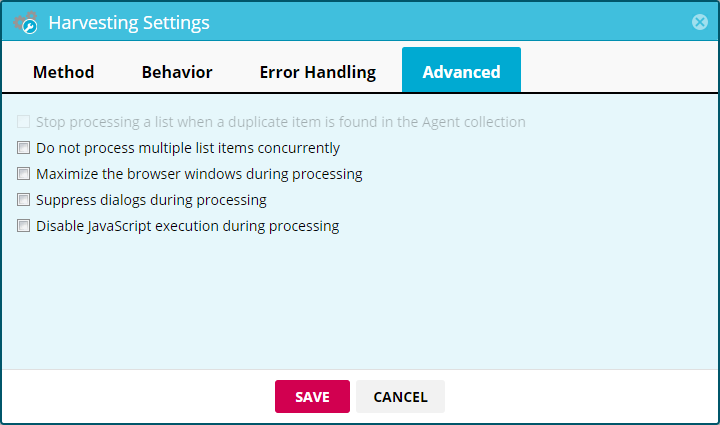
Stop processing a list when a duplicate item is found in the agent collection*
Default: off. This setting allows you to stop an agent from using excessive page credits when gathering data from a website with ordered items, such as a news organization with chronological posts. After defining unique fields, the job will be stopped when a duplicate item is detected. Like tracking changes, this option will be greyed out unless unique fields are defined.
Do not process multiple list items concurrently
Default: off. By default, Mozenda’s harvesting servers split list-based tasks into multiple threads, which speeds up processing. This may, however, cause problems on websites that use AJAX or other methods for navigation and sorting.
If a job returns duplicate or incorrect data, this setting may be the solution. Note that enabling this option will slow down the agent.
Maximize the browser windows during processing
Default: off. Mozenda’s harvesting servers process a browser window at a much smaller size compared to a normal desktop, which can lead to some websites serving different content. If an agent cannot find website elements or finds the wrong information, maximizing the window could help.
Suppress dialogs during processing
Default: off. Most websites don’t display popups, ads, or other dialogs that interfere with Mozenda, but there are cases where this setting may help.
Disable JavaScript execution during processing
Default: off. This setting is available for two main reasons: speed and compatibility.
Disabling JavaScript in any browser will result in reduced load times, including the Agent Builder. Keep in mind that JavaScript is used in many websites to add visual effects and/or functionality, so you will want to test an agent thoroughly to ensure that data extraction will continue to work.
In some cases, a website will stop working due to JavaScript errors. In these cases, disabling JavaScript will allow the job to complete normally. To troubleshoot this, track down the point of failure and use the Agent Builder to test that specific page with and without JavaScript enabled. Note that this setting can also be controlled via the Agent Builder settings and will sync with the Web Console.
Additional Notes
If a project requires similar settings to be used across multiple agents, you can standardize these easily using agent groups. Settings can be applied to existing agents or add a new agent to an existing group to carry the settings over automatically.
One important aspect of dealing with website errors is to understand error handling. Marking an item as “optional” will skip over missing data, but using a dedicated error handling page allows you to get real feedback on why something isn’t available.
We’re Here to Help
There are a lot of qualifiers in the solutions presented above, and with good reason: every website is unique, and the answer to an issue with a particular agent will vary.
When in doubt, reach out to our support department at support@mozenda.com or 801.995.4550.